Chú thích của người dịch: Tính năng tạo trước cache (prebuild cache) rất thú vị, nó giúp người truy cập ngay lần đầu tiên vào trang đã có tốc độ cao nhất có thể. Nếu không bật, thì chỉ những lượt truy cập thứ hai trở đi mới có tốc độ tốt. Đáng tiếc là để tránh quá tải (chủ yếu do lo sợ người dùng thiết lập sai), đa số công ty host sẽ khóa crawler, chỉ trừ khi dùng VPS hoặc máy chủ thuộc toàn quyền của bạn thì bạn mới chủ động được hoàn toàn việc này.
Bài này là bổ trợ hữu ích cho những ai muốn tùy biến sâu plugin LiteSpeed Cache (bài tôi đã dịch của Johnny Nguyen). Vì đây là tài liệu hướng dẫn được viết bởi chính chủ nên lắm từ kỹ thuật & ngôn ngữ hơi khô, anh chị em chịu khó, kiên nhẫn…
OK, giờ chúng ta bắt đầu tìm hiểu nhé.
Crawler sẽ quét toàn trang web của bạn, làm mới (tạo lại cache) cho trang đã hết hạn cache. Điều này giúp cho người truy cập ít có khả năng phải vào các trang chưa được cache (tốc độ sẽ chậm hơn trang đã được cache).
Crawler phải được bật ở cấp độ máy chủ hoặc cấp độ virtual host bởi admin quản trị website.
Tab summary / tổng quan
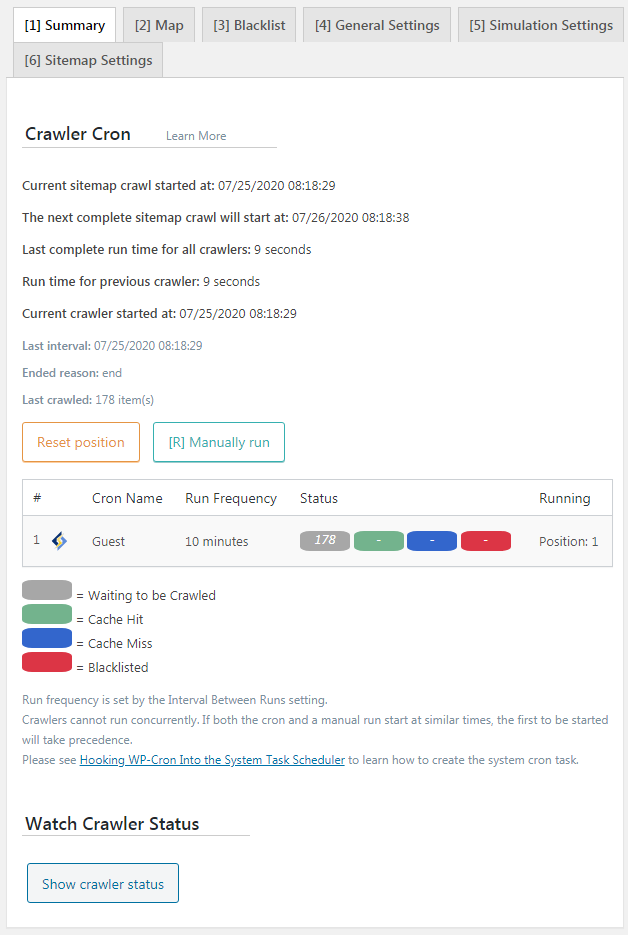
Crawler Cron
- Bạn thấy các tiến trình của nhiều crawler khác nhau được bật trên website của bạn. Bạn có thể theo dõi quá trình của từng crawler thông qua mã màu của hình chữ nhật trong cột Status.
- Sử dụng nút Reset Positions để khởi động lại crawler tại thời điểm bắt đầu.
- Sử dụng nút Manually run để khởi động crawler mà không cần đợi cron job.
Xem trạng thái crawler / Watch crawler status
- Nếu bạn chọn xem trạng thái crawler, màn hình của bạn sẽ trông giống như hình bên dưới. Thông điệp trong cửa sổ trạng thái sẽ không giống nhau trên các website khác nhau.
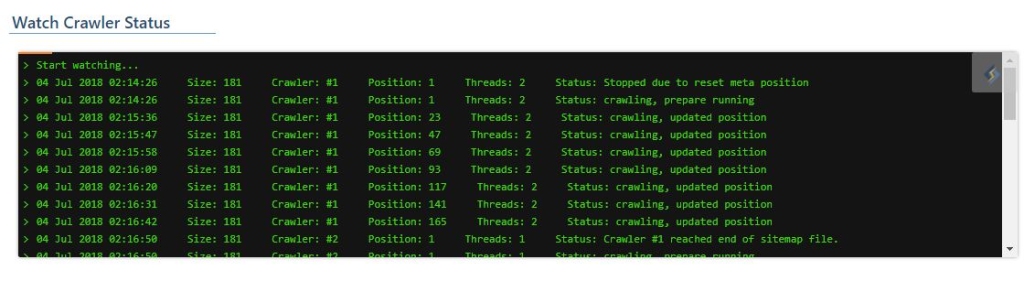
Dưới đây là giải thích cho một số thuật ngữ:
- Size: Số lượng URL trong sitemap. Trong ví dụ trên là 181
- Crawler: Chỉ ra số crawler bạn đang xem. Số 1 trong ví dụ trên. Có thể có nhiều crawler cùng hoạt động, phụ thuộc vào cài đặt của bạn cụ thể như thế nào.
- Position: Số URL hiện đang được tìm nạp từ danh sách của sitemap.
- Threads: Chỉ ra số lượng threads hiện đang được dùng để tìm nạp URL. Có thể có đồng thời nhiều thread được tìm nạp. Cái này được điều chỉnh dựa trên cài đặt của bạn.
Tab map
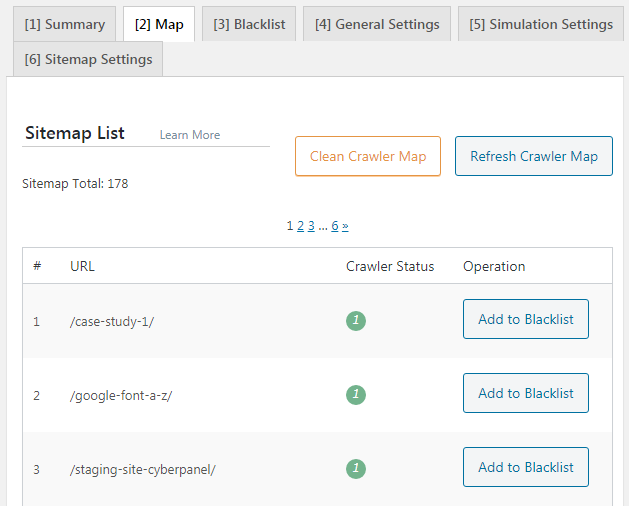
Sitemap List / Danh sách sitemap
- Trang này hiển thị các URI hiện có trong crawler map. Nếu bạn không nhìn thấy bất kỳ danh sách nào, hãy thử nhấn nút Refresh Crawler Map.
- Ở phần này bạn có thể thêm thủ công URI vào danh sách đen (blacklist) thông qua nút bên cạnh mỗi bài.
- Cột trạng thái Crawler (crawler status) sử dụng chấm màu để cho bạn biết trạng thái của từng URI. Xem phần bên dưới bảng để hiểu ý nghĩa.
- Để bắt đầu từ đầu với crawler map, bạn hãy nhấn nút Clean Crawler Map.
Tab blacklist / danh sách đen
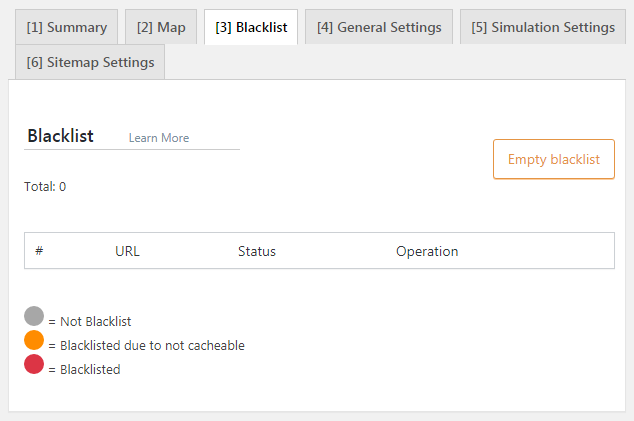
- Trang này hiển thị các URI hiện đang được đưa vào trong blacklist.
- Từ đây bạn có thể loại bỏ thủ công các URI từ blacklist thông qua nút bên cạnh mỗi mục.
- Cột Status sử dụng các chấm màu để cho bạn thấy trạng thái của từng URI. Xem chú thích bên dưới bảng để hiểu ý nghĩa.
- Để bắt đầu từ đầu và xóa blacklist, hãy nhấn nút Empty Blacklist.
Tab cài đặt chung / general settings
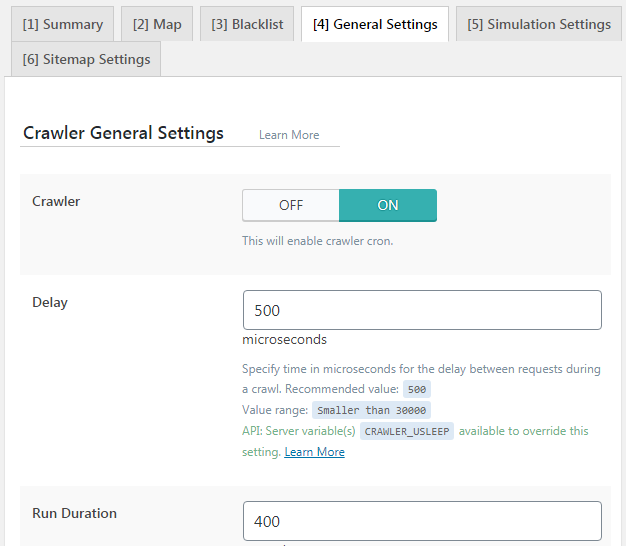
Crawler
- Bạn để là ON để bật crawling cho website.
Delay
- Giá trị mặc định là 500 mili giây. Đây là thông số cho LiteSpeed Cache biết mức độ thường xuyên trong việc gửi yêu cầu mới đến máy chủ của bạn. Bạn có thể tăng giá trị này lên để giảm tải cho máy chủ, tất nhiên khi làm vậy quá trình crawling toàn bộ trang sẽ mất thời gian hơn.
Cài đặt này có thể bị giới hạn ở cấp độ máy chủ, bạn có thể muốn tìm hiểu thêm thông tin về ảnh hưởng của crawler tác động lên máy chủ của bạn (có thể tôi sẽ dịch sau).
Run Duration
- Giá trị mặc định 400. Đây là độ dài thời gian tính theo giây crawler chạy trước khi tạm dừng. Sau khi quá trình nghỉ kết thúc, crawler sẽ bắt đầu lại tại chính xác vị trí mà nó đã rời đi lúc nãy và chạy thêm 400 giây nữa. Quá trình này cứ lặp đi lặp lại cho đến khi toàn bộ website được crawled.
Interval Between Runs
- Giá trị mặc định 600. Cài đặt này chỉ định độ dài thời gian nghỉ đề cập ở trên. Theo mặc định crawler sẽ nghỉ 600 giây trước khi tiếp tục chạy 400 giây.
Crawl Interval
- Giá trị mặc định 302400. Giá trị này chỉ định độ dài cần đợi trước khi bắt đầu lại toàn bộ quá trình crawling. Để trang web của bạn được crawled thường xuyên, hãy xác định độ dài thời gian crawler thường chạy, và thiết lập giá trị lâu hơn thế một chút.
Threads
- Giá trị mặc định 3. Đây là con số chỉ định quá trình crawling riêng rẽ xảy ra đồng thời. Giá trị này càng cao, website của bạn được crawled càng nhanh, nhưng dĩ nhiên nó làm máy chủ của bạn vất vả hơn.
Timeout
- Giá trị mặc định 30. Đây là khoảng thời gian tính theo giây mà crawler có để crawl một trang cụ thể trước khi chuyển sang trang kế tiếp. Giá trị có thể nằm trong khoảng từ 10 đến 300 giây.
Server IP
- Giá trị mặc định chuỗi rỗng (không điền gì). Từ phiên bản 1.1.1, bạn có thể nhập địa chỉ IP của trang để đơn giản hóa quá trình crawling và loại bỏ công sức, thời gian liên quan đến tìm kiếm DNS và CDN. Để hiểu lý do, hãy đặt một vài giả thuyết (kịch bản) sau.
Đây là cách nó hoạt động nếu bạn sử dụng CDN:
- Crawler lấy đường dẫn http://yourserver.com/path của bạn thông qua sitemap.
- Crawler kiểm tra DNS để tìm địa chỉ IP của yourserver.com
- DNS trả về địa chỉ IP của CDN cho crawler
- Crawler đi tới CDN để yêu cầu trang
- CDN lấy trang từ yourserver.com
- CDN trả trang về cho crawler
Đây là cách nó hoạt động nếu bạn không sử dụng CDN:
- Crawler lấy đường dẫn http://yourserver.com/path của bạn thông qua sitemap
- Crawler kiểm tra với DNS để tìm địa chỉ IP của yourserver.com
- Crawler lấy trang của bạn từ yourserver.com
Trong cả hai kịch bản trên, bạn mất thời gian tìm kiếm và cần nhiều tài nguyên hơn. Các tìm kiếm như vậy có thể được loại trừ bằng cách nhập địa chỉ IP trang của bạn trong trường này.
Khi crawler biết địa chỉ IP của bạn, đây là cách nó hoạt động:
- Crawler lấy đường dẫn http://yourserver.com/path từ sitemap của bạn
- Crawler lấy trang trực tiếp từ yourserver.com vì nó đã biết trước địa chỉ IP rồi
Các thành phần trung gian bị loại bỏ, kèm với tất cả chi phí, thời gian của chúng.
PS: Để biết địa chỉ IP của máy chủ web của bạn là gì. Ngay bên dưới trường Server IP, có đường link Check my public IP from DoAPI.us, bạn click vào để kiểm tra.
Server Load Limit
- Giá trị mặc định là 1. Tùy chọn này là cách để crawler tránh độc chiếm tài nguyên hệ thống. Một khi nó đạt đến giới hạn, crawler sẽ bị ngắt thay vì để nó làm ảnh hưởng xấu đến tài nguyên máy chủ. Cài đặt này dựa trên Linux server load. (Một máy tính hoàn toàn nhãn rồi có tải trung bình là 0. Mỗi quá trình chạy hoặc sử dụng hoặc đợi cho tài nguyên CPU thêm 1 vào tải trung bình).
- Cài đặt này có thể được giới hạn ở cấp độ máy chủ. Bạn có thể tìm hiểu thêm về cách giới hạn ảnh hưởng của crawler lên máy chủ.
Tab cài đặt mô phỏng / simulation settings
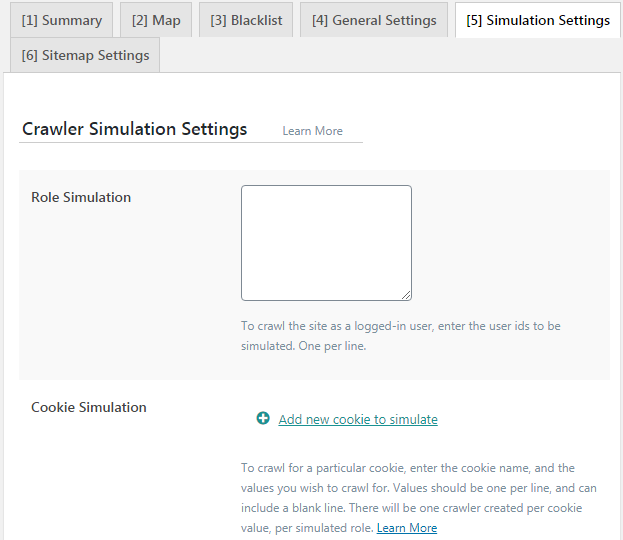
Role Simulation
- Giá trị mặc định chuỗi rỗng. Mặc định crawler sẽ chạy dưới dạng khách ghé thăm không-đăng-nhập (non-logged-in user) trên website của bạn. Cũng như vậy, trang sẽ được cache bởi crawler ở mô hình người dùng không-đăng-nhập. Nếu bạn thích tạo cache trước theo mô hình người dùng đã đăng nhập, bạn có thể thực hiện ở đây.
- Crawler mô phỏng tài khoản người dùng khi nó chạy, vì thế bạn cần chỉ định cụ thể id của người dùng tương ứng với vai trò mà bạn muốn cache.
Ví dụ để cache trang cho người dùng với vai trò “Subscriber”, bạn hãy chọn một người dùng ở vai trò subscriber, và nhập ID của người dùng đó vào trong box.
- Bạn cũng có thể crawl nhiều mô hình người dùng bằng cách nhập vào nhiều id vào bên trong box, mỗi cái một dòng.
Lưu ý: Chỉ một crawler chạy vào một thời điểm, vì thế nếu bạn có nhiều id user trong box Role Simualtion thì crawler “Guest/Khách” sẽ chạy trước tiên, rồi sau đó các crawler tương ứng với từng vai trò- mới được chạy theo thứ tự lần lượt từng cái một.
Cookie Simulation
- Để crawl cho một cookies cụ thể, bạn nhập tên cookie vào đây, và giá trị bạn muốn crawl. Các giá trị phải được điền theo từng dòng, và có thể bao gồm dòng trống (blank line). Sẽ có một crawler tạo cho từng giá trị cookie, tương ứng với từng vai trò. Nhấn nút + để thêm các cookies bổ sung, nhưng bạn cần ý thức được rằng số lượng crawler sẽ tăng lên nhanh chóng cùng với mỗi cookies mới và có thể làm ảnh hưởng xấu đến tài nguyên hệ thống.
Ví dụ nếu bạn crawl cho vai trò Guest và Administrator, bạn có thể thêm testcookie1 với các giá trị A và B, bạn có 4 crawlers:
- Guest, testcookie1=A
- Guest, testcookie1=B
- Administrator, testcookie1=A
- Administrator, testcookie1=B
Và testcookie2 với giá trị C, D và bạn sẽ có số lượng crawler tăng lên nhanh chóng: 12 cái.
- Guest, testcookie1=A, testcookie2=C
- Guest, testcookie1=B, testcookie2=C
- Administrator, testcookie1=A, testcookie2=C
- Administrator, testcookie1=B, testcookie2=C
- Guest, testcookie1=A, testcookie2=D
- Guest, testcookie1=B, testcookie2=D
- Administrator, testcookie1=A, testcookie2=
- Administrator, testcookie1=B, testcookie2=
- Guest, testcookie1=A, testcookie2=
- Guest, testcookie1=B, testcookie2=
- Administrator, testcookie1=A, testcookie2=
- Administrator, testcookie1=B, testcookie2=
Không có nhiều tình huống mà bạn cần phải sử dụng crawler theo mô hình cookie, nhưng nó có thể hữu ích trên các trang sử dụng cookie để điều chỉnh đa ngôn ngữ hoặc tiền tệ.
Ví dụ WPML sử dụng cookie _icl_current_language= để thiết lập ngôn ngữ khác nhau cho người dùng. Người dùng nói tiếng Anh có thể sẽ có cookie kiểu như _icl_current_language=EN, trong khi người dùng nói tiếng Việt có thể có cookie như _icl_current_language=VI. Để crawl trang của bạn cho một ngôn ngữ cụ thể, sử dụng user Guest và giá trị cookie thích hợp tương ứng.
Tab cài đặt sitemap / sitemap settings
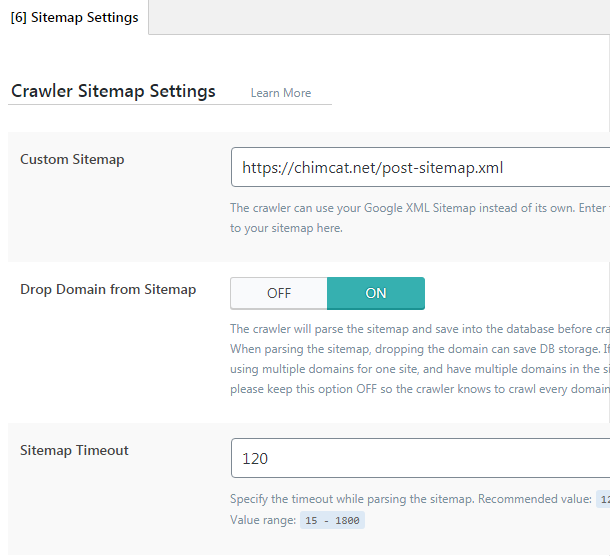
Custom Sitemap
- Giá trị mặc định là chuỗi rỗng (empty string/không điền gì). Sitemap nói cho crawler biết các trang nào trên website của bạn cần crawler. Theo mặc định, plugin LiteSpeed Cache cho WordPress sẽ tự tạo sitemap riêng của nó. Tuy vậy nếu bạn đã có sitemap rồi và bạn thích sử dụng nó hơn thì đây là tùy chọn khả dụng bắt đầu từ phiên bản 1.1.1
- Bạn nhập URL đầy đủ của sitemap vào trường này. Lưu ý là sitemap cần phải tuân thủ định dạng chuẩn của Google XML Sitemap
Drop Domain from Sitemap
- Giá trị mặc định là ON. Crawler sẽ phân tích sitemap và lưu nó vào trong cơ sở dữ liệu trước khi crawling. Khi phân tích sitemap, việc loại bỏ tên miền có thể giúp tiết kiệm dữ liệu lưu trữ.
Lưu ý: Nếu bạn sử dụng nhiều tên miền trên cùng một site, và bạn có nhiều tên miền trong sitemap, bạn cần để tùy chọn này là OFF. nếu không crawler sẽ chỉ crawl được một tên miền trong số này.
Sitemap Generation
Sử dụng trường này nếu bạn không có sẵn sitemap tùy chỉnh để dùng.
Include Posts / Pages / Categories / Tags
- Giá trị mặc định ON. Có bốn cài đặt giúp bạn chỉ định taxonomies nào sẽ được crawled. Theo mặc định thì nó bao gồm tất cả.
Exclude Custom Post Types
- Giá trị mặc định chuỗi rỗng. Theo mặc định tất cả taxonomies sẽ được crawled. Nếu bạn có một số cái không cần crawled, hãy liệt kê chúng ở đây, mỗi cái một dòng.
Order Links By
- Giá trị mặc định Date, descending (Ngày tháng, giảm dần). Trường này dùng để chỉ định thứ tự crawler sẽ được thực hiện để phân tích sitemap. Mặc định nó ưu tiên cho các nội dung mới nhất trên website của bạn. Thiết lập giá trị này cho phép các nội dung quan trọng nhất được crawled trước, điều này quan trọng bởi vì crawler sẽ tạm dừng tương đối nhiều lần (cụ thể còn tùy thuộc vào độ lớn trang và cài đặt của bạn) thì mới có thể hoàn thành crawled được toàn bộ sitemap.
![Tùy chỉnh tính năng Crawler trong plugin LiteSpeed Cache [tài liệu hướng dẫn chính thức]](https://kiencang.net/wp-content/uploads/2023/09/cache-html-cdn-300x157.png)
![Tùy chỉnh tính năng Crawler trong plugin LiteSpeed Cache [tài liệu hướng dẫn chính thức]](https://kiencang.net/wp-content/uploads/2023/09/CDN-cache-html-300x157.png)
![Tùy chỉnh tính năng Crawler trong plugin LiteSpeed Cache [tài liệu hướng dẫn chính thức]](https://kiencang.net/wp-content/uploads/2022/07/ty-le-cache-cao-300x157.png)